Overall project
The ultimate goal of USTC_Software 2010 team is to promote synthetic biology throughout the world. To attract more people who do not have biology background to be interested in this area, we plan to develop a modeling-and-simulation game specially designed for synthetic biology. Users are taught to learn the basic knowledge in the area via constructing their genetic circuits as input to our software and try to understand the system behavior as output. This is the basic functional module. We also plan to develop a rating system to grade users' design for given tasks, and a more friendly game interface that can fill the process of input with joy and ease. Though more functions are expected, we focus on the basic module, modeling-and-simulation, at the first stage of our project.
In practice, many CAD (Computer-Aided Design) tools, such as TinkerCell and Synbioss, have been developed to model and simulate biological systems and give the system behaviors as guides. However, they all need users to provide details of the system network, such as the activation and repression of transcription and translation reactions in genetic regulatory network. It is so difficult for even professionals to construct a detailed network of a complex system depending only on their minds. In this sense, modeling through CAD tools will not reduce the work of modeling: users are actually required to model manually and input their model in details.
However, since our software is developed for non-biological background users, it is unrealistic to expect them to model their design manually. To solve this problem, the USTC_Software 2010 team attempts to take synthetic biology modeling one step further by introducing new methods for automatic modeling of biological systems. Just as the word automation implies, users are only required to submit their assembling of parts, and the generation of biological model is automatically done by our program. Being the first-ever team trying to develop a synthetic biology automatic modeling tool, we focus on genetic regulatory network for the first year and develop our software tool, iGaME, which will assist the design of genetic function modules for biological systems in synthetic biology. We believe this will greatly relieve users from handling complex interactions of species in biological system.
Many novel and revolutionary concepts are proposed during our development. The first is our Chain-Node model for complex structure with multiple chains bound together. It is necessary for automation since behaviors of species (such as how it react with other species) must be determined by their structures instead of their names: it is impossible to construct a universal name-based reaction database applying for different systems. The next is Template. A species with a certain structure is a template species, and a reaction occurring between several template species is a template reaction. The introduction of Template makes it possible to describe a group of reactions with same structure-determined reaction mechanism. Finally, based on our Chain-Node and Template concept, we propose an XML-based Standard Biological Part Automatic Modeling Database Language (MoDeL for abbreviation) to fully characterize Species and Reaction in templates with clear definitions of elements and attributes in XML fashion. It is a database language for next generation when automatic modeling is widely used throughout the world.
Though we have no enough time to achieve our ultimate goal completely, we have successfully developed a MoDeL-based, automatic modeling and simulation software. Our program falls into 3 major components. The first component is user interface. Users could give their assembling of parts by drag-and-drop function and setup initial conditions as well. System behavior as output will also be shown there. The second component is database written in MoDeL, which is the kernel of our automatic modeling idea. The last component is our core program designed to support MoDeL language. It functions as a driver: completing system network based on users' input and data stored in our database to give dynamic analysis as output.
First look at our features
Bring Biological Modeling to the Next Level
| Chain-Node Model (Figure. 1) is a brand new Complex Modeling Concept incorporating detailed structure description with universal applicability. Instead of treating complex as a whole while ignoring their basic composition and structure, Chain-Node Model view complex as a construction of it basic Parts. Just as its name implies, our model includes two components: Chain and Node. As a correspondence to natural polymer chains, each Chain is consisted of an arrangement of its basic unit, Part, whose concept has been greatly extended. Parts include but not limited to Biobrick Parts.
| 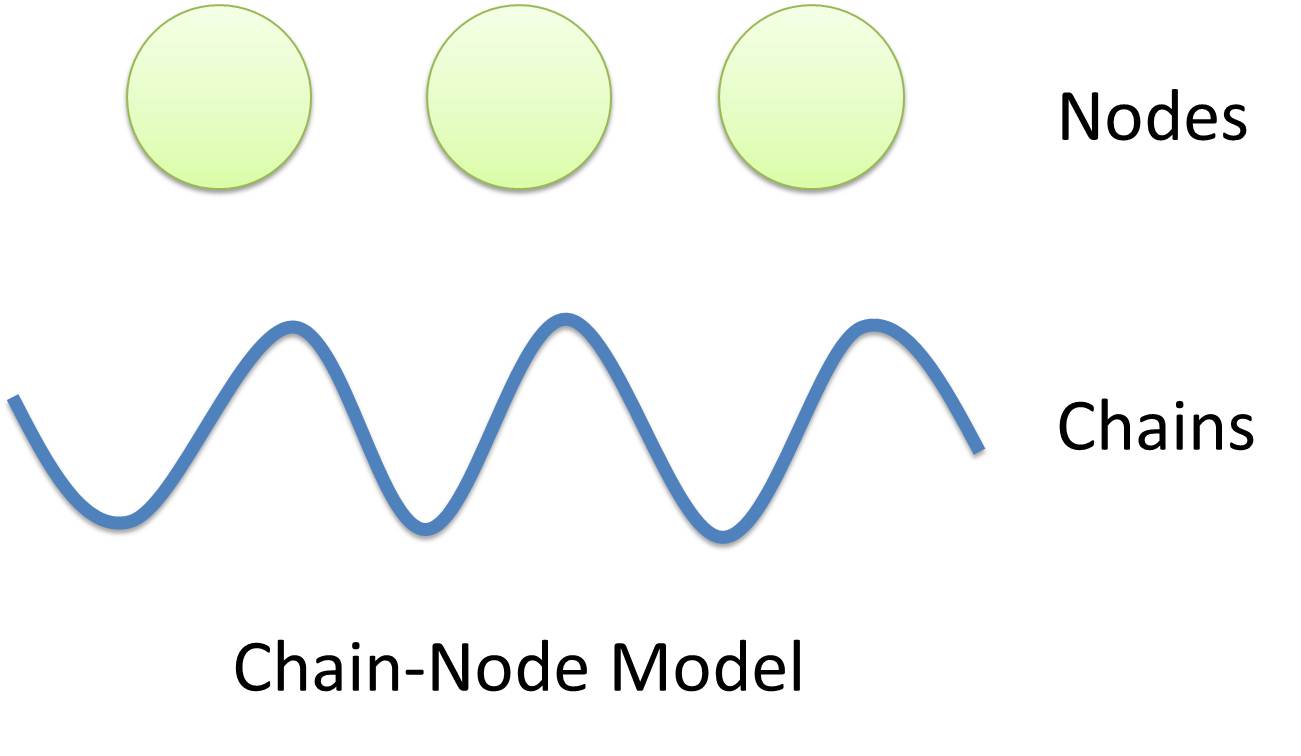 Figure 1: Logo of Chain-Node Model |
| The Node component does not have a natural correspondence. It is an abstract concept to describe binding states of two or more parts: each binding will create a Node. The abstract nodes may continue to bind with other parts or nodes to form a tree structure. However, parts or nodes in bound states are not allowed to bind again. With the help of chains and nodes, it is possible to model any complex with arbitrary architecture. Simple and inaccurate modeling of biological process could not keep pace with the development of synthetic biology and undoubtedly, our Chain-Node model provides a possible solution to the imbalance.
|
| A simple example, tetR dimer, is shown to illustrate our simple modeling idea (做一个tetR2的模型放在右边做为配图,否则右边太空了). It has two chains with each containing only one part, tetR. Dimerization of tetR will create a node to indicate the bound state of two parts. To explain more clearly, bound parts are also considered as nodes so that in this example, all nodes are organized in a tree structure, which includes two children (leaf) nodes and one parent node. We will conform to this convention in our wiki.
| Figure 1: Logo of Chain-Node Model |
| To know more, users are suggested to read this One-Minute Introduction to have an intuitive idea of our modeling system.
|
Modeling with Templates
| Modeling manually of biological system is widely used for synthetic biology modeling but it requires an overall understanding of the biological network. It is difficult for even professionals to provide such large amount of data. The underlying reason making modeling so difficult is that the data provided manually are redundant because different reactions may occur through different mechanisms. Based on this. we are always seeking feasible ways to implement our automatic modeling idea. The automatic does not mean modeling without any information provided, but however, there indeed exists a minimal data set to enable the automation. The minimal data set is the Templates. Similar to C++ programming language, we introduce templates to allow generic description of species and reactions of a certain structural pattern or reaction mechanism.
There are two kinds of templates: species templates and reaction templates. A template species behaves like species except that the template can have unknown parts of many different types. In other words, a species template represents a family of species. To apply this idea, we design a special part, ANY, of class Substituent, to represent unknown parts of any length on one chain. For example, a species with structure ANY - pTetR - ANY represents any species with part pTetR. A reaction template provides a specification for generating reactions with the same mechanism. Species in reaction templates are all templates, too. This could be understood more clearly by interpreting the known parts of species templates as the functional group -- a reaction template describes the interaction mechanism of these functional groups. For example (去做一个合适的example), pTetR promoter is deactivated in presence of TetR dimer which usually occupies the RNA polymerase binding site of pTetR sequence. The template species are pTetR template and TetR dimer template (see Figure) and the functional groups are pTetR promoter and TetR dimer. Any pair of species which partially contain pTetR DNA and TetR protein dimer respectively would bind according to the description of this reaction template. Modeling with templates allows users to define species and reactions only once for one certain family without rewriting them again in database.
|
|
Automatic Modeling Database Language
| The data used for automatic modeling should be well organized. For this purpose, we construct a database in unified format and make it machine-readable. Since everyone is allowed to add, delete or modify data stored in the database, each component of the database must be specified to a clear format, which defines a standard database language. We call it MoDeL: Modeling Database Language by picking out characters from three words. MoDeL is based on XML language, which makes it flexible and extensible. For more specifications of MoDeL, click here.
|  Figure 3: A peek at our database |
|
|
|
|
|
 "
"


