
Self-inducible promoters

Integrative standard vector for E. coli
The integration of the genetic circuits of interest into the microbial host genome can eliminate the need of expensive selection techniques, such as antibiotics or auxotrophic media, in cell cultures.
In order to simplify the engineering of the host genome, two standard and modular integrative vectors have been designed for Escherichia coli and Saccharomyces cerevisiae, two commonly used hosts for industrial protein production. Here, a detailed description of the integrative vector for E. coli is reported, while the following section deals with the integrative vector for yeast.
The structure of the designed vector, here named <partinfo>BBa_K300000</partinfo>, is shown in Fig.1. Most of its features have been inspired by <partinfo>BBa_I51020</partinfo> (BioBrick base vector) and <partinfo>BBa_J72007</partinfo> (BamHI methyltransferase encoding CRIM plasmid), described by [Shetty RP et al., 2008] and [Anderson JC et al., 2010] respectively.
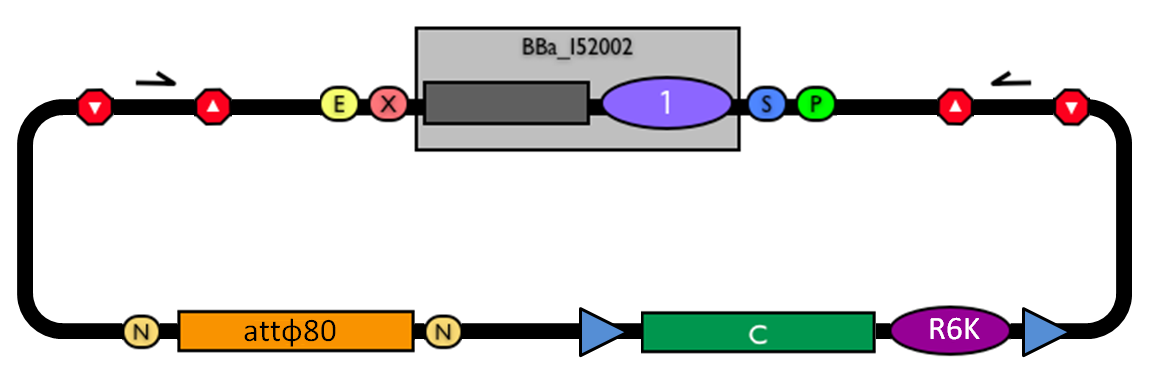 BioBrick integrative base vector BBa_K300000. |
|
This vector can be considered as a base vector, which can be specialized to target the desired integration site in the host genome. The default version of this backbone has the bacteriophage Phi80 attP (<partinfo>BBa_K300991</partinfo>) as integration site.
This vector enables multiple integrations in different positions of the same genome.
Glossary
The passenger is the desired DNA part to be integrated into the genome.
The guide is the DNA sequence that is used to target the passenger into a specific locus in the genome.
The main design features for vector engineering and for the genome integration of the vector are reported below.
Vector engineering features:
- The cloning site is compatible with the original BioBrick standard (RFC10), i.e. it is composed by the BioBrick Prefix (<partinfo>BBa_G00000</partinfo>) and Suffix (<partinfo>BBa_G00001</partinfo>). The presence of illegal restriction sites (XbaI in <partinfo>BBa_J72001</partinfo> and SpeI in <partinfo>BBa_K300991</partinfo>) prevents the usage of this backbone in the classic BioBrick Standard Assembly process. However, the presence of unique EcoRI and PstI sites in Prefix and Suffix fully supports the assembly of the desired BioBrick parts in the cloning site upon EcoRI-PstI digestion and also supports the 3A Assembly.
- The two NheI restriction sites flanking the default integration guide sequence <partinfo>BBa_K300991</partinfo> enable the engineering of this backbone by assembling new user-defined BioBrick integration guides upon XbaI-SpeI digestion, if the desired guide conforms to the RFC10 or a compatible standard.
- The default insert <partinfo>BBa_I52002</partinfo> contains the positive selection marker <partinfo>BBa_P1016</partinfo> and the pUC19-derived replication origin <partinfo>BBa_I50022</partinfo>. <partinfo>BBa_P1016</partinfo> expresses the ccdB toxin gene, which is lethal for most E. coli strains and is useful to prevent the growth of transformants containing the uncut plasmid contaminant DNA. For this reason, the default vector must be propagated in ccdB-tolerant strains, such as DB3.1 (<partinfo>BBa_V1005</partinfo>). <partinfo>BBa_I50022</partinfo> enables the propagation of this vector at high copy in the used ccdB-tolerant strain.
- Like in many other standard vector backbones (e.g. the pSB**5 series), the binding sites for standard primers VF2 (<partinfo>BBa_G00100</partinfo>) and VR (<partinfo>BBa_G00102</partinfo>) are present upstream and downstream of the BioBrick cloning site respectively. These two sequences are sufficiently distant from the cloning site to enable a good quality sequencing of the insert.
Genome integration features:
- The four transcriptional terminators <partinfo>BBa_B0053</partinfo>, <partinfo>BBa_B0054</partinfo>, <partinfo>BBa_B0055</partinfo> and <partinfo>BBa_B0062</partinfo> ensure the transcriptional insulation of the integrated part from its flanking genome sequences.
- The two FRT recombination sites (<partinfo>BBa_J72001</partinfo>) enable the excision of <partinfo>BBa_K300994</partinfo>-<partinfo>BBa_K300998</partinfo>-<partinfo>BBa_G0001</partinfo>-<partinfo>BBa_B0025</partinfo>-<partinfo>BBa_G0001</partinfo>-<partinfo>BBa_K300999</partinfo>-<partinfo>BBa_K300995</partinfo> (i.e. the R6K origin and the Chloramphenicol resistance marker) upon Flp recombinase activity. This marker excision allows users to make multiple integrations in the same strain, always using the same antibiotic resistance marker.
- The engineering of the integration guide allows the integration of parts in user-defined genome positions and for this reason this vector supports the integration by exploiting bacteriophage attP-mediated integration as well as homologous recombination.
How to use it
<partinfo>BBa_K300000</partinfo> can be:
- propagated in E. coli
- engineered to change the passenger and/or the integration guide
- integrated into the desired locus of the host genome
- used to perform the desired number of serial integrations in the same genome
How to propagate it before performing genome integration
The default version of this vector contains the <partinfo>BBa_I52002</partinfo> insert, so it *must* be propagated in a ccdB-tolerant strain such as DB3.1 (<partinfo>BBa_V1005</partinfo>).
After the insertion of the desired BioBrick part in the cloning site, this vector does not contain a standard replication origin anymore, so it *must* be propagated in a pir+ or pir-116 strain such as BW25141 (<partinfo>BBa_K300984</partinfo>) or BW23474 (<partinfo>BBa_K300985</partinfo>) that can replicate the R6K conditional origin (<partinfo>BBa_J61001</partinfo>).
How to engineer it
The DNA guide can be changed as follows:
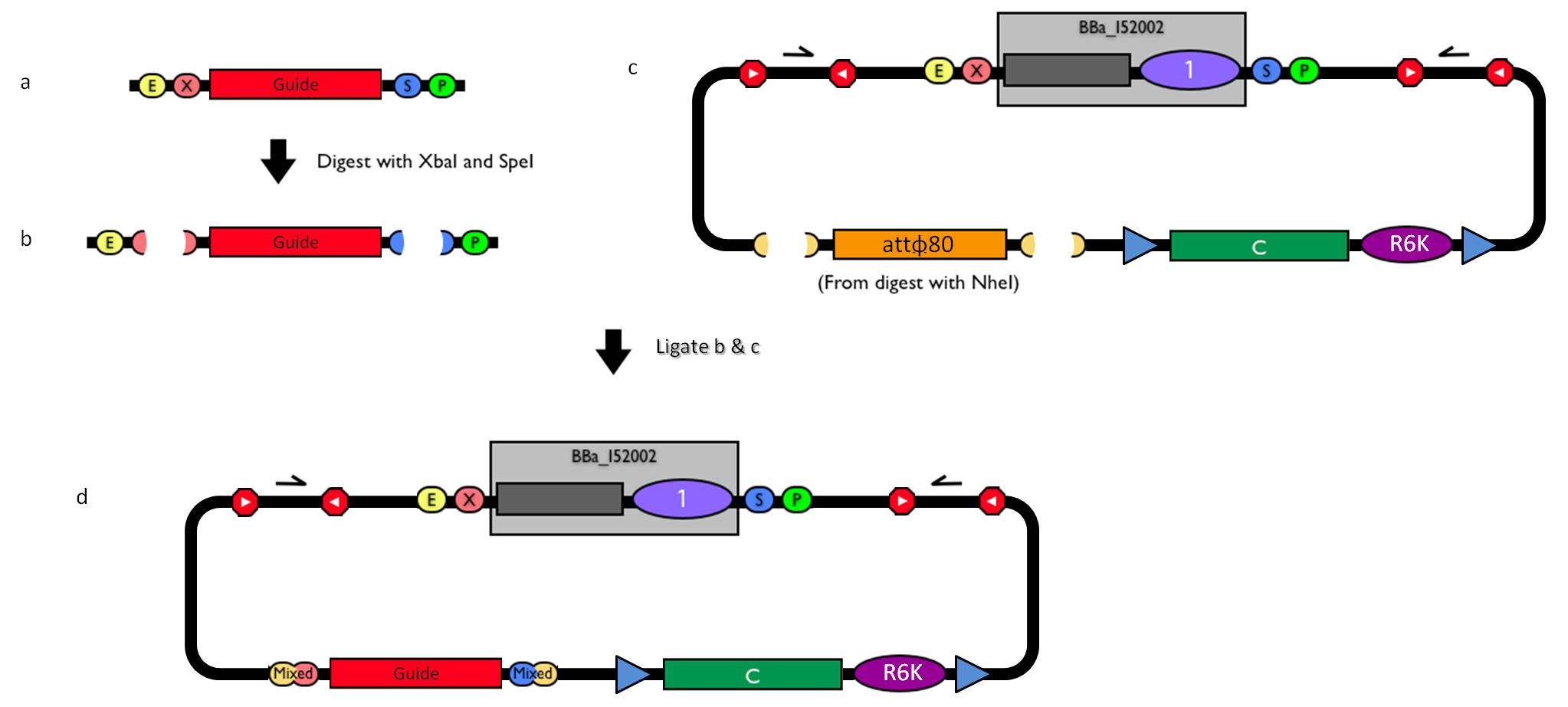 How to engineer the integrative base vector to assemble the desired DNA guide. |
- Be sure to have the desired guide in the RFC10 standard or a compatible one (Fig.1-a).
- Digest the guide with XbaI-SpeI (Fig.1-b).
- Digest the integrative base vector <partinfo>BBa_K300000</partinfo> with NheI (Fig.1-c) and dephosphorylate the linearized vector to prevent re-ligation.
- Ligate the digestion products (Fig.1-d). XbaI, SpeI and NheI all have compatible protruding ends. Note that the ligation is not directional, but the guide can work in both directions.
- Transform the ligation in a ccdB-tolerant strain and screen the clone.
The DNA passenger can be changed as follows:
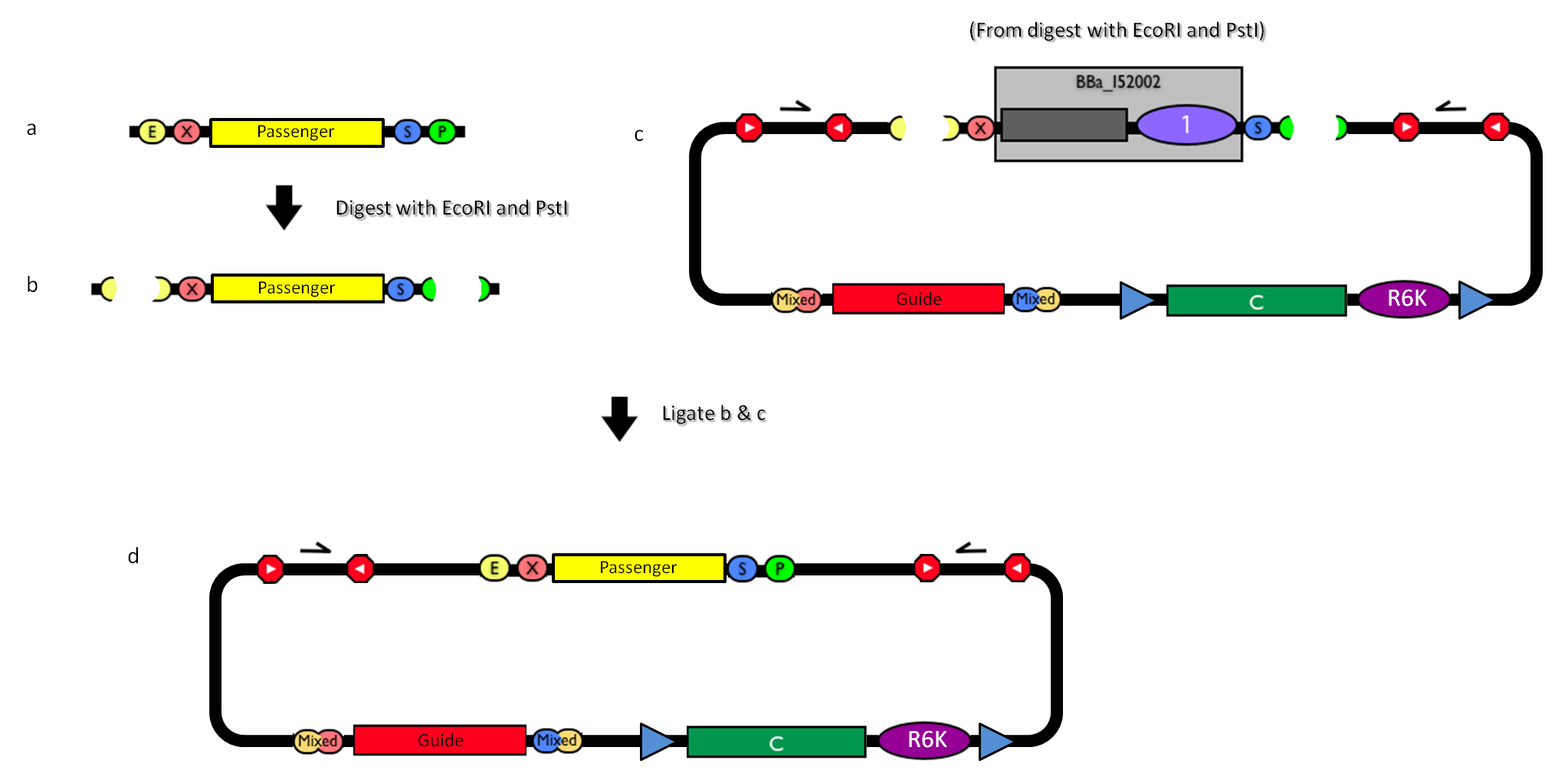 How to engineer the integrative base vector to assemble the desired DNA passenger. |
- Be sure to have the desired passenger in the RFC10 standard or a compatible one (Fig.2-a).
- Digest the passenger with EcoRI-PstI (Fig.2-b).
- Digest the integrative base vector <partinfo>BBa_K300000</partinfo> with EcoRI-PstI (Fig.2-c).
- Ligate the digestion products (Fig.2-d).
- Transform the ligation in a pir+/pir-116 strain. Transformants with the uncut plasmid contaminant DNA do not grow because of the ccdB toxin in <partinfo>BBa_I52002</partinfo>. Screen the clone.
How to perform genome integration
The integration into the E. coli chromosome can exploit the bacteriophage attP-mediated integration or the homologous recombination.
Detailed protocols about attP-mediated integration can be found here:
- Anderson JC et al., 2010
- Haldimann A and Wanner BL, 2001
Detailed protocols about homologous recombination can be found here:
- Martinez-Morales F et al., 1999
- Posfai G et al., 1997
When using the default integration guide <partinfo>BBa_K300991</partinfo>, the integration method relies on the bacteriophage site-specific recombination (attP-mediated recombination) through the attP site on the integrative vector and the attB site in the host genome.
This integration method is applicable when the host strain does not have prophages in the att(Phi80) locus. TOP10 (<partinfo>BBa_V1009</partinfo>) and DH5alpha (<partinfo>BBa_V1001</partinfo>) strains have the Phi80 prophage and so their chromosome cannot be engineered with this procedure.
The genomic integration of the desired BioBrick part into the attP(Phi80) locus has to be mediated by co-transforming a helper plasmid (such as the Amp-resistant <partinfo>BBa_J72008</partinfo> plasmid) carrying the IntPhi80 site-specific integrase gene under the control of a thermoinducible promoter (see Fig.???). The helper plasmid also has a heat-sensitive replication origin, whose replication can be inhibited at temperatures of 37-42°C, while a permissive temperature for this vector is 30°C. For this reason, it can be cured at high temperatures, when the integrase expression is triggered at the same time.
The Phi80 integrase mediates the site-specific recombination between the attP site in the integrative vector and the attB site in the bacterial genome (for a schematic description of this process, see Fig.???).
Thanks to its R6K conditional replication origin, the integrative vector cannot be replicated in common E. coli strains, so the Chloramphenicol resistant bacteria are actual integrants.
In the Materials and Methods section, a detailed protocol to target the desired BioBrick part into the Phi80 locus is reported.
How to perform multiple integration in the same genome
When this vector is integrated into the genome, the desired passenger should be maintained into the host, as well as the Chloramphenicol resistance marker and the R6K conditional replication origin. The CmR and the R6K can be excised from the genome by exploiting the two FRT recombination sites that flank them. The Flp recombinase protein mediates this recombination event, so it has to be expressed by a helper plasmid, such as pCP20 (CGSC#7629).
This enables the sequential integration of several parts using the same antibiotic resistance marker, which can be eliminated each time.
Detailed protocols about homologous recombination can be found here:
- Cherepanov PP and Wackernagel W, 1995
- Datsenko KA and Wanner BL, 2000
Materials and Methods
Plasmids and strains: the <partinfo>BBa_J72008</partinfo> helper plasmid was kindly given by Prof. JC Anderson (UC Berkeley). MC1061 (<partinfo>BBa_K300078</partinfo>) and MG1655 (<partinfo>BBa_V1000</partinfo>) E. coli strains and the pCP20 helper plasmid were purchased from the Coli Genetic Stock Center (Yale University). DH5alpha (<partinfo>BBa_V1001</partinfo>) strain was purchased from Invitrogen.
Verification primers: all the oligonucleotides were purchased from Primm (San Raffaele Biomedical Science Park, Milan, Italy). The P1 (<partinfo>BBa_K300975</partinfo>) and P4 (<partinfo>BBa_K300978</partinfo>) primers had already been used in [Anderson JC et al., 2010]. The P2 (<partinfo>BBa_K300976</partinfo>) and P3 (<partinfo>BBa_K300977</partinfo>) primers have been newly designed using ApE and amplifiX. P2 and P3 have been designed also considering the previously used verification primers P2 and P3 in the pG80ko integrative plasmid, described in [DeLoache W, 2009].
Competent cells preparation: all the E. coli strains were made competent following a slightly modified version of the protocol described in [Sambrook J et al., 1989]. Briefly, cells were grown to and OD600 of ~0.4-0.6, harvested (4000 rpm, 10 min, 4°C) and the supernatant discarded. Cells were resuspended in (30 ml for each 50 ml of initial culture) pre-chilled Mg-Ca buffer (80 mM MgCl2, 20 mM CaCl2), centrifuged as before and the supernatant discarded. Cells were resuspended in (2 ml for each 50 ml of initial culture) pre-chilled Ca buffer (100 mM CaCl2, 15% glycerol), aliquoted in 0.5 ml tubes and freezed immediately at -80°C. Test the transformation efficiency as:
efficiency [CFU/ug of DNA]= # CFU * 1000 ng of DNA / amount of transformed DNA [ng]

Integrative standard vector for yeast

Self-cleaving affinity tags to easily purify proteins
 "
"








